Nowadays, when implementing a .NET application that works directly with a database (relational or not), most developers will chose Entity Framework Core to abstract their data layer and work directly with entity classes.
It has become an integral part of the .NET ecosystem, just like ASP.NET, and it is extremely rare finding someone that never worked with it. I’ve been using it myself ever since version 4 (along with other ORMs) and I must say that it aged like a fine wine.
Fully open sourced, with support for multiple databases (not just SQL Server) while offering relatively optimized and extensible conversion from LINQ to database queries, accessing data from a .NET application never been easier. And when it doesn’t support something, just integrate with some micro ORM and go crazy on that SQL!
One core feature is the implementation of the unit of work pattern by supporting, what is usually called, a first level cache. Load a bunch of entities from the database, that will be tracked in memory by the context, mutate or delete them, create new ones and then flush everything in a single database access.
The thing about this feature, despite working fine most of the time, is that it depends on managing internal state with mutable entities. After all, it was originally focused on C# developers that were used to work in a object-oriented way — get an entity, change some properties, request an update.
But what if you are a C# developer and prefer the advantages provided by immutability?
Lets look at the most used immutable class in the .NET world — the string.
We all know that working with text can be memory inefficient if badly managed, but imagine a world were you could initialize a string with the name “Bruce Wayne”, pass it as an argument to some method that was supposed to count how many words were in it, and when you realize, your original string contains the name “Peter Parker” because the strings were mutable and nothing could prevent that?
In this article I won’t enter into details about the advantages of immutable over mutable objects, and vice versa. There are great articles already explaining both visions and we all know no size fits all, so it kinda depends of your current needs.
But I’m going to explain how you can use immutable entities directly with Entity Framework Core so you know that not only it is possible but also a viable option.
Immutable entities in C#
Before C# 9 the only way to create an immutable entity was to define a class or structure with getter only properties that were initialized during object construction, ensuring nothing could be changed afterwards.
As an example, a PersonEntity would look like this:
1 | public class PersonEntity |
It works as expected but there is one major problem: just by looking at the code, the developer cannot tell which properties are being set unless argument names are used and, if it wants to change something, it must copy every property by hand.
1 | var person = new PersonEntity( |
For small POCOs this may not be a problem, but for bigger ones the chances of someone making a mistake increases.
With this in mind, Microsoft implemented init only setters supporting object initializers while still preventing changes afterwards. Couple this with record types, and creating immutable entities has never been easier in C#.
The same PersonEntity, but now using both of these features:
1 | public record PersonEntity |
Not only the syntax is more concise by using auto-implemented properties, you can now easily tell which properties are being set during initialization and have a much easier life copying data by using the keyword with and only state which properties must change.
1 | var person = new PersonEntity |
Change Tracking and immutability
Every developer that uses Entity Framework knows it provides a lot of database abstractions to enable working directly with .NET objects.
One core feature is the automatic detection of changes made to entities. This usually means interacting with the context to get an existing entity, change some properties and then invoke SaveChangesAsync which will generate a bunch of instructions and execute them into the database. Under the hood, when the entity is retrieved from the context it will keep a reference to the instance and original values from the database and when the developer requests the context to save changes, all properties of tracked entities will be compared and if anything changed, instructions will be generated and executed.
This works well for mutable entities but we are implementing immutability, and since no changes will be made to tracked entities, will this cause any issues?
Let’s imagine the following use case:
- You retrieve our Bruce Wayne from the database using an EF Core context, which internally will keep a reference to it;
- You want to change it’s birthdate, so you clone it while assigning a new date;
- If you invoke
SaveChangesAsync, nothing will happen because no changes happened to the original entity; - If you invoke
Update, anInvalidOperationExceptionwill be thrown because the context is already tracking an entity with the same primary key;
Certainly invoking SaveChangesAsync and nothing happening was expected, after all we created a copy of the original instance, which EF Core knows nothing about and would never automatically detect changes, but why the exception when trying to attach the entity to the context?
This leads to another EF Core feature, called Identity Resolution, strongly correlated to our change tracking.
Identity Resolution ensures the same entity is retrieved for the same primary key while being tracked. This is a requirement when implementing the Unit of Work pattern because EF Core only flushes data when SaveChangesAsync is invoked.
Again, let’s imagine our PersonEntity was a mutable class:
- You retrieve our Bruce Wayne from the database using an EF Core context, which internally will keep a reference to it, also identified by its primary key;
- You change its birthdate;
- You do some more work;
- You try to get it again from the EF Core context but since that primary key its already being tracked, it returns the same instance instead of going to the database and returning old data for your Unit of Work operation;
- You change more properties;
- Invoke
SaveChangesAsync, flushing changes and now both the instance and database have the same data;
As you can see, Identity Resolution is important for mutable entities, but not so much for our use case and it’s a problem we must solve.
The project
It seems the only thing preventing an immutable approach to database access while using EF Core is not relying on Change Tracking for mutations while preventing Identity Resolution problems.
Let’s create a C# console application that will use Entity Framework Core to store data into a SQLite database, using immutable record entities.
The source code is available on GitHub, feel free to give it a look.
Setup
Start by opening Visual Studio and creating a .NET 6.0 Console Application with a name at any location you prefer.
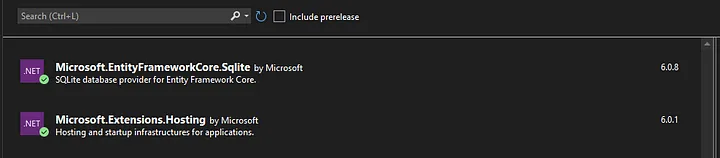
Install most recent versions of Entity Framework Core for SQLite and Microsoft hosting nugets:
Microsoft.Extensions.HostingMicrosoft.EntityFrameworkCore.Sqlite
Create a ProgramHost class implementing IHostedService. This class will run our exemple code, but for now just inject a logger and write something inside the StartAsync method. We’ll do nothing in the StopAsync method, so just return a completed task.
1 | public class ProgramHost : IHostedService |
Open the Program.cs file, build an host with our ProgramHost class registered as a hosted service.
1 | using var host = Host.CreateDefaultBuilder() |
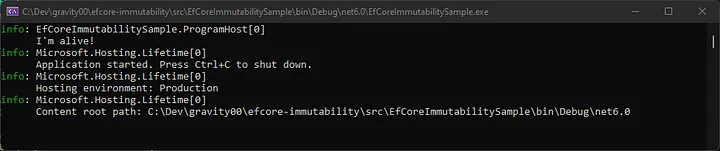
If you configured everything correctly and run the application, you should see something like this:
The database model
For simplicity, we’ll have a single Persons table:
- Id — identity column to uniquely identify the row (required);
- Forename — stores the first name (text, required);
- Surname — stores the last name (text, required);
- MiddleNames — stores the middle names (text, optional);
- Birthdate — stores the date of birth (date, optional);
When representing database entities, I always create a base class containing properties to be defined in all entities (like the unique identifier or some metadata columns), and for the rest I always use positional records syntax for required properties and auto-properties for optional ones, making clear to the developer which ones must be always provided (this also removes compiler warnings if the project is configured for nullable reference types).
1 | /// <summary> |
If you prefer to keep everything more compact, feel free to use positional records with default values for optional properties.
1 | public record PersonEntity( |
This is the most compact syntax, but be careful when adding new optional properties if your are sharing records across multiple applications. It will also be considered a breaking change unless you define both constructors, effectively losing this compact syntax. That’s the reason I don’t use positional record syntax for everything, but it kinda depends on your needs.
Now, lets create our EF Core context with Persons table mappings.
1 | public class SampleDbContext : DbContext |
Open the Program.cs file and register the EF Core context into the container. This is a test console, so I’ll use the temporary folder to store the SQLite file but feel free to use any other location and file name.
1 | using var host = Host.CreateDefaultBuilder() |
Now inject the context into the ProgramHost class and, since this is a test console and we want to freely modify our entities without much thought, change the StartAsync method to always drop and recreate the database on startup.
1 | public class ProgramHost : IHostedService |
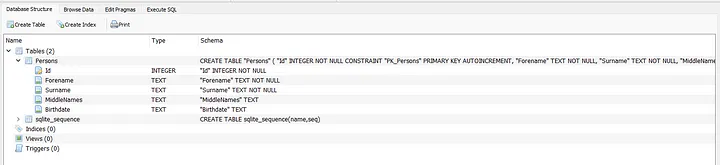
If you run the application and open the SQLite database file (using DB Browser for SQLite or equivalent), both a Persons and sqlite_sequence tables should be defined.
Configuring for immutability
Now that we have a working solution lets recall what we need to achieve to support immutability:
- Not relying on Change Tracking to know which instructions must be executed when
SaveChangesAsyncis invoked; - Preventing Identity Resolution exceptions;
Because Change Tracking is such a core feature in Entity Framework Core, you can only disable it when querying for entities.
As stated in Microsoft documentation, we can disable it in three ways:
- Using extension method
AsNoTrackingfor each query; - Setting context property
ChangeTracker.QueryTrackingBehaviortoNoTracking; - Global configuration with method
UseQueryTrackingBehavior;
Open Program.cs file and disable it globally, ensuring will never be tracked when queried from the database.
1 | using var host = Host.CreateDefaultBuilder() |
In theory, if you only made a single entity operation per unit of work, like getting a person by unique identifier, changing its middle names and doing an update, this configuration would be enough.
Sadly we all know development is far from perfect and more complex applications, due to business requirements, may lead to multiple updates to the same data in a single unit of work operation. That’s one of the major reasons behind Change Tracking in EF Core, to implement the unit of work pattern while not relying on database ACID implementations and reducing the time transactions stays open.
This means every time an entity is added, updated or removed using the context, an internal reference will be kept and Identity Resolution exceptions will be thrown if someone tries to attach an entity with the same id.
There are multiple ways to solve this problem but the easiest one is to enforce a transaction, flush changes to the database every time a create, update or delete is requested and then detach the entity.
Since this is a proof of concept application, I’m going to implementing this behavior with extension methods over DbContext instances, but feel free to wrap it into a repository pattern or any way you prefer.
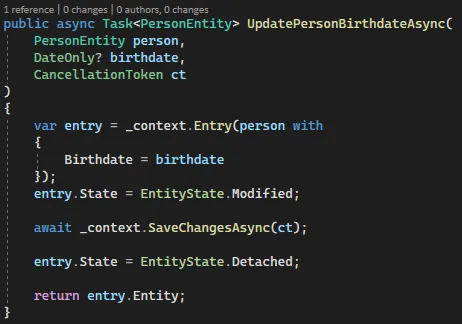
Create a static class DbContextExtensions and implement a generic extension that will receive an entity and the state to be tracked, returning an updated entity.
1 | public static class DbContextExtensions |
The method creates an EntityEntry<TEntity>, changes the state to the one provided and immediately requests to flush changes. Because the context is now tracking the entity, it will execute a database instruction based on the entry state (Added|Modified|Deleted). Then, it detaches the entity right before returning to prevent Identity Resolution exceptions on future mutations and returns the entity with the most recent values (usefull to get values generated by the database, like an identity column).
Open the ProgramHost class and create some test code using the extension method and the immutable PersonEntity. In this case I’m creating Bruce Wayne and then updating both birthdate and middle name.
1 | public class ProgramHost : IHostedService |
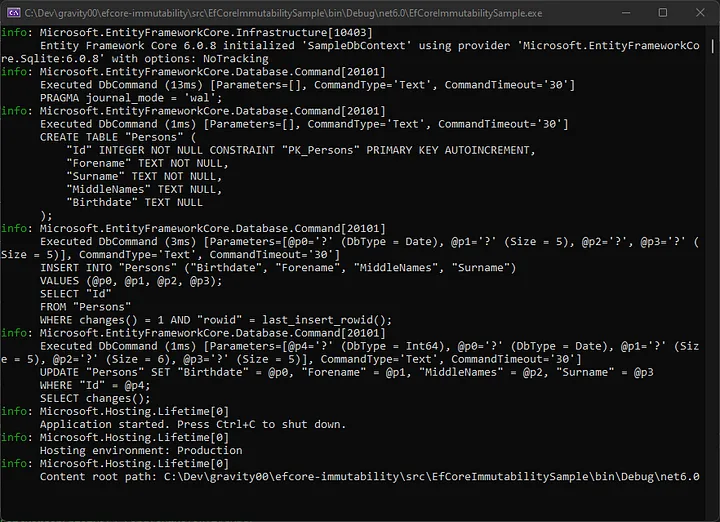
If you execute the code, you’ll see database instructions being sent to SQLite by Entity Framework Core to insert and then update the entity.
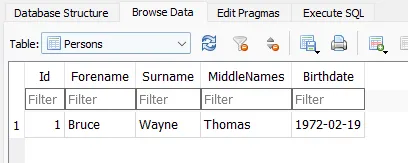
Open the SQLite file and you’ll see Bruce Wayne was both created and updated with a birthdate and middle name.
Certainly you don’t want to be writing EntityState.Added|Updated|Deleted every time an entity needs to be manipulated, so lets create dedicated extensions for each operation and update your test code.
Change the method to private and implement a CreateAsync, UpdateAsync and DeleteAsync extension methods that will reuse the existing one.
1 | public static class DbContextExtensions |
Use the new methods in our ProgramHost class.
1 | public class ProgramHost : IHostedService |
Conclusion
I hope this article gave you a good idea on how to use Entity Framework Core to abstract your application from the database while still implementing the immutable design pattern to manage application state.
There are both advantages and disadvantages of using immutable entities over mutable ones, after all no size fits all, but I think its nice to know you have the option to use it without sacrificing productivity by having to implement database access yourself. As long you ensure Change Tracking is disabled for all queries and every code uses your abstractions to create, update or delete entities, everything will work just fine.
Just a small note about explicit database transactions. If you are implementing an ASP.NET Core application and using the mediator pattern, some time ago I created a bunch of articles and one of them provided an approach to manage Entity Framework Core transactions globally using a pipeline. I use that approach all the time, you may find it helpful too.